Departures from vanilla git
Most of the silent movies that will ever be made have already been made. But most of the people who will use git aren't using it yet. So rather than focus on the people who already use git, we have made some departures from "vanilla" git usage in order to make adoption easier for people who haven't used git or version control before.
Here are some of the ways we've departed:
No index / staging area
In vanilla git, the working copy consists of three trees of files:
- The parent commit snapshot
- The working copy folder
- The "index" or "staging area"
When you do git commit, the index is forged into a new commit. In order to make a commit, you need to move files from the working copy folder into the index. You can continue to make edits after putting a file in the index, so you end up with three different versions - one in your parent commit, one in your working copy folder, and one in the index.
Here are just a few of the commands needed to manage this "index" mechanism:
git add <filename>adds a file to the indexgit add --patch <filename>adds hunks of a file to the indexgit reset --mixedsets the index to match the parent commitgit ls-indexfor looking at files in the indexgit diff-indexfor diffing files in the index
In DiffPlug, we ignore the index entirely. If a file is checked in the commit window, then it will be put into the commit. Simple as that.
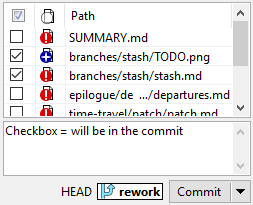
No stash
It's common to have a situation where you've done a bunch of work that you'd like to save, but you're not ready for it to be a real commit yet - you just want to keep it for later.
Vanilla git handles this with git stash. Because there are two places where changes can be - the working copy folder and the index - git has to do something pretty complicated. It makes one commit to save the index, and a second merge commit which saves the working copy and references the index commit.
![]()
It stores these as "refs/stash". If you call git stash a second time, it uses the reflog to keep the first stash around for a while.
Because it doesn't make a regular branch with regular commits, you can't use regular commands to get the changes back. Instead, you have to learn the various flags and subcommands of git stash.
Rather than introducing an entirely new mechanism for users to learn, DiffPlug handles this use case with the save for later functionality, which just uses regular branches and commits.
No detached head
Vanilla git supports a "detached head" mode, which allows a user to not have a branch. Rather than support this exceptional case, DiffPlug converts it into a nominal case by automatically creating and checking out a new branch named detachedHead-deleteme. If that is already a branch, DiffPlug adds a suffix to make the name unique.
A user is never able to enter the "detached head" mode from within DiffPlug, but this ensures nominal operation in case they use DiffPlug with another tool (e.g. the command line) that results in a detached head state.
Renamed the commit manipulation commands
cherry-pickis nowapply deltarevertis nowunapply deltacheckout <paths>is nowapply content
When a user clicks a commit, the tool shows them the changes which it introduced. When they right click that commit and see cherry-pick as an option, they ask themselves, "what does this do?" And the answer is: it applies the changes in this commit. The natural thing is to just call it apply.
Of course, this causes some conflicts with the CLI. git apply takes changes from an external source and applies them to HEAD. git cherry-pick extracts changes from the history, and applies them to HEAD.
One of the problems with a CLI is that it's hard for the user to express context. When a user right-clicks a commit or right-clicks a patch file, the GUI program knows what the context is. In a CLI, the user would either have to pass some kind of flag git apply --from-commit, or you could just make a whole new command to handle this case, as was done with git cherry-pick.
No push/pull
Most git guides will say something like "use git pull to download changes, and then git push origin master to upload them". Everybody already knows the words "upload" and "download", what's the point of confusing things with "pull" and "push"?
Also, git pull doesn't just download, it also merges your branch into whatever branch it is "tracking", unless perhaps you've set one of three global flags which causes pull to perform a rebase instead of merge.
If you can see the history branch at every step, then you don't need complex commands which automatically take local actions, which is why we only teach "upload" and "download".